Project Goldfinch
Distilling Large Language Models into Dialogue Graphs
(Alexa Socialbot Grand Challenge 5 Science Innovation Winner)

Introduction
Recently, neural large language models (LLMs) have produced great progress in the conversational domain and have been brought to the fore of public attention. [1][2] Compared to traditional chatbot setups based on dialogue trees [3], LLMs have the advantages of being broad, flexible, and fluent: they enable conversations across a breadth of domains and handle novel situations gracefully [4]. However, these models also have glaring weaknesses that limit their effectiveness as the sole backend of a chatbot. In particular, (1) LLMs are not factual: they often hallucinate and can contradict themselves when given a slightly reworded prompt; (2) LLMs are not controllable, and can steer from topic to topic in a suboptimal manner; (3) LLMs are risky and and produce toxic output in unexpected scenarios, and it is not easy to edit such responses to make the model more predictable.
What if we could build a system that brought together the flexibility of neural dialogue and the controllable ease of traditional rule-based methods?
As part of the Stanford Alexa Prize Team this year, I was the research lead for project Goldfinch, a project that distilling neural generations into a dialogue tree. Taking inspiration from the self-play mechanism of AlphaZero, we consider a conversation of game of 'turns': each turn is a singular pair of chatbot and human utterances in a conversation. Every chatbot utterance is represented as a node in a directed acyclic graph, while user responses are represented as directed edges that transition to another chatbot 'turn'.
Our goal here is to leverage the intuition of large language models to generate a declarative dialogue tree that would otherwise take months (and perhaps years) of manual engineering and human development. Here's how we do it:
(Note: This blog post assumes some basic knowledge of CAMEL. You can read more about it here)
Pipeline
The goldfinch pipeline consists of two main parts: a widening phase, and a deepening phase. Each turn of conversation is represented in a CAMEL supernode, and the widening process refers to the procedure of generating rules and responses for a posed chatbot question. Then, to generate further conversation, we follow up our widening of a supernode with a deepening procedure. This term refers to the process of generating follow-up questions and new supernodes to branch off of a chosen starting point.
Widening
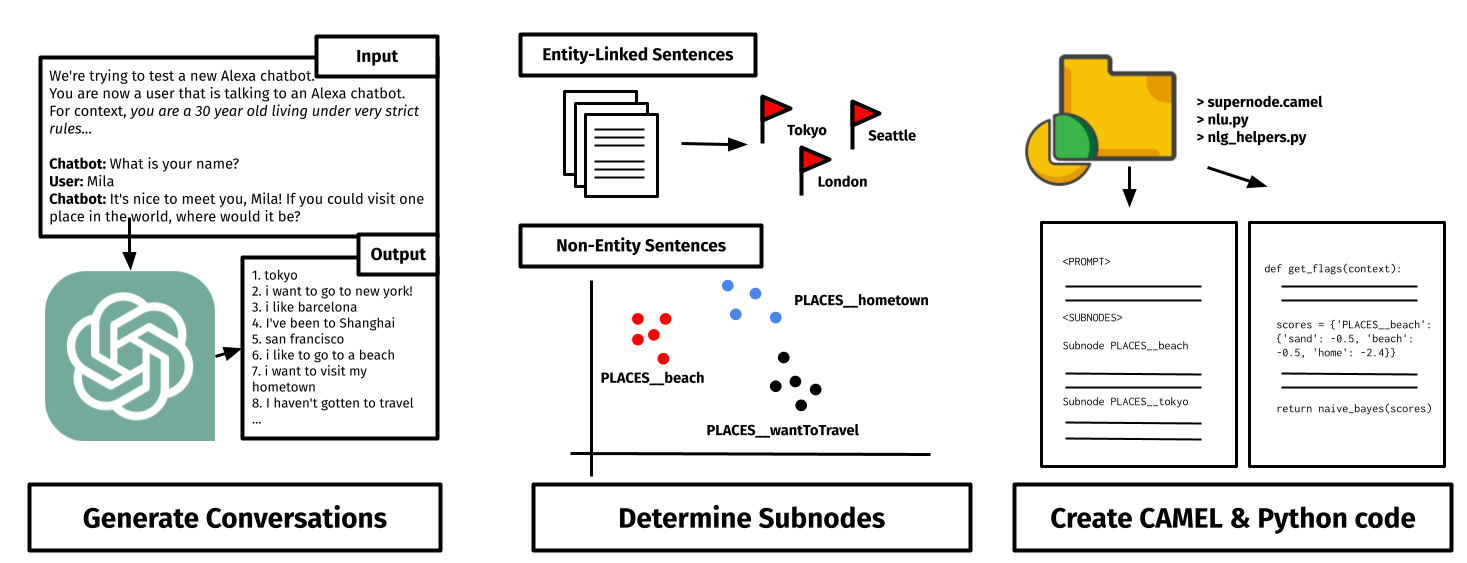
This diagram showcases the three steps of the widening process that we do before deepening: we generate conversations, then determine subnodes, and then we create CAMEL and Python code.
User Response Generation: We begin with LLM User Generation: we prompt a GPT-3.5 to produce user-like utterances. Following PersonaChat by Facebook AI, we add personas to improve the variety of generations, generating a total of 200 utterances. These personalities range from questioning speakers to low-initiative and adversarial users -- these all are difficult scenarios to map out with dialogue trees.
For high-traffic nodes to improve pre-existing supernodes, we also use the most common user utterances as simulated user utterances -- when doing this, we use a privately hosted Falcon-40B LLM to respect user data privacy requirements.
Clustering of Possible User Responses: Once these ~200 conversations are generated, our goal is to combine similar utterances, and map out the possibilities that the bot should respond to at inference time. We consider three cases of user responses:
- If the user's response names an entity by our EL engine, we cluster all such responses together.
- If the user's response does not explicitly name a Wikipedia entity, we use an LLM prompt to find the 'pseudo-entity'. We will then generate a specialized subnode if it this entity appears often enough in simulation.
- For all other non-entity specific utterances, we use affinity propagation to cluster non-entity utterances on their SentenceBERT embeddings, aiming to group semantically similar user responses together. We choose affinity propagation as our clustering model for the task, as it is particularly well suited for problems for which the optimal number of clusters is unknown.
This procedure usually maps out 50 to 60 possible scenarios alongside a default fallback scenario.
Code Generation: Our goal is to generate suitable responses and sorting algorithms to use at inference time.
First, our goal is to create rules to sort user utterances at inference time into the correct pre-determined possible scenario. For all entity-based clusters, this is quite simple: we can use the entity linker alongside keyword search to determine the suitable cluster. However, for non-entity utterances grouped by our affinity propagation model, the procedure is a bit more complicated: we expand each cluster using paraphrases, then perform Naive Bayes to build interpretable rules for each cluster.
Now, using a LLM, we propose a possible response to each cluster which is an adequate response to each of the user responses in the cluster. This is done at this later step of the Goldfinch pipeline in order to reduce the redundancy of generating multiple responses to a single scenario.
These serve as the building blocks that are converted into CAMEL code and python logic to complete the Goldfinch widening process.
Deepening
Of course, a single turn of dialogue does not make a conversation. Thus, the next step is to lay the foundation for a follow-up discussion for each newly-generated subnode.
We prompt a large language model to simulate follow-up questions for each subnode by including the entire conversational history in the context, specifying the level of answer specificity as appropriate. For specific entity subnodes, we request a specific question that shows interest and knowledge of the subject at hand; for non-specific subnodes, we ask for a generalized question that asks the user for further discussion on their opinion or the subject. Due to the exponential nature of deepening, our conversations are set by default to two turns of deterministic supernode questions, followed by a neural response; exceptions to this setting are granted based on experimental traffic.
Selective Deepening: A major shortcoming of Goldfinch is the aforementioned exponential nature of deepening and the supernode-subnode structure. If every supernode has a lower bound of n designated subnode responses, then generating a unique follow-up supernode for a starting supernode will result in n2 unique subnode responses after two turns of conversation, and nkover k turns of conversation. While this process may allow Chirpy Cardinal to build up specific domain knowledge on a multitude of topics, the number of nodes becomes completely unmanageable at a certain depth of discussion. As a result, our team utilizes selective deepening, which allows us to deactivate follow-up supernodes that are rarely triggered in our experimental traffic. At the same time, our analytics can also inform us on follow-up supernodes that we should widen for more fulfilling conversations. While this process is currently a manual process, we aim to further automate this in the future.
Results
For the Alexa Prize, we generated over 2,000 supernodes with Goldfinch. Overall, our Goldfinched nodes were received well by users: we observe that conversations that reach our active, more general Goldfinched supernodes scored an average conversation rating of 3.59, compared to an average of 3.24 without, from March to June.
To avoid ratings-based noise, we also evaluated Goldfinch with GPT-3.5 [5]. We used these to both evaluate the impact of Goldfinch altogether and the impact of deepening conversations (i.e., recursively applying Goldfinch to produce deep conversations). For the former, we prompted the LLM to compare sample conversations from a Goldfinched-PLACES supernode and its previous handwritten version. The LLM preferred Goldfinched conversations with a p-value of 0.00002. For the latter, we compared conversations in our RELAXATION specialization that were deepened with Goldfinch to those by a neural model. The LLM preferred Goldfinched conversations with a p-value of 0.0098.
Conclusion
End-to-end neural chatbots may seem tempting for the wide variety of advantages it brings. Neural models are flexible: they are able to handle a wide variety of user responses, even in unusual or unexpected situations. Additionally, neural models have high fluency: given chat history, neural models are great at continuing the flow of the conversation with impressive dialogue quality.
However, until we can solve the issues with latency or conversation flow, our best compromise is a hybrid system: we use neural generation whenever possible, but leverage human intuition for conversational flow and structure. Goldfinch is a novel approach to solving these bottlenecks, and we hope it will serve as an inspiration for other work in the future.
References
[1] OpenAI, 2023. GPT Technical Report
[2] Romal Thoppilan, Daniel De Freitas, Jamie Hall, Noam Shazeer, Apoorv Kulshreshtha, Heng-Tze Cheng, Alicia Jin, Taylor Bos, Leslie Baker, Yu Du, et al. 2022. Lamda: Language models for dialog applications. arXiv preprint arXiv:2201.08239
[3] Boris Galitsky and Dmitry Ilvovsky. 2017. Chatbot with a discourse structure-driven dialogue management. In Proceedings of the Software Demonstrations of the 15th Conference of the European Chapter of the Association for Computational Linguistics, pages 87–90.
[4] Jiaxin Huang, Shixiang Shane Gu, Le Hou, Yuexin Wu, Xuezhi Wang, Hongkun Yu, and Jiawei Han. 2022. Large language models can self-improve. arXiv preprint arXiv:2210.11610.
[5] Cheng-Han Chiang and Hung yi Lee. 2023. Can large language models be an alternative to human evaluations? ACL.
back