The Importance of Prompt Engineering

Don’t tell anyone!
I’ll let you in on a secret: OpenAI’s GPT-3 model has been powering a few of my own software-related projects. Though other companies, i.e. DeepMind, Baidu for Chinese have supposedly constructed similar models behind closed doors, GPT-3 is unique in that its API is accessible by the general public (programmers, researchers like us) and can be used to build commercial applications by any programmer in their bedroom. That being said, GPT-3 is not a magic wand: as we wait for other GPT-n iterations to be released to the general public, it’s important to acknowledge the importance of prompt engineering in obtaining state-of-the-art results.
Introduction
To begin, GPT-3 is a large language model (LLM) designed by the research lab of OpenAI based in San Francisco. In general, these models have been trained on billions upon billions of tokens to predict a probability distribution over sequence of words. Large language models are useful in reading, summarizing, and predicting future words in a sentence; for this reason, they are often used in the field of text generation.
There have been recent advancements in the technical applications of GPT-3: apart from being used in Microsoft products to translate language into computer code, it’s become scaringly good at writing essays. The Guardian published an article here written by GPT-3 itself, describing how AIs like itself are completely harmless. After all, in its release paper, OpenAI reported that its 80 American subjects were asked to classify 200-word articles as human or GPT3-generated, and were only able to guess correctly 52% of the time (essentially random).
So, if the models are so great, why aren’t they used more ubiquitously?
The Problem
Models like GPT-3 have the capacity to generate cohesive essays and, quite impressively, flow through unrelated concepts and paragraphs with decent – albeit robotic – style. Yet they are limited in their understanding of the world! As a motivating example, consider the domain of basic integer operations. Here, GPT-3 will struggle with even multiplication questions containing three and four digit numbers. When setting the model to 0 temperature (meaning that it will only output the most likely sequence to follow), I ask OpenAI the basic mathematical question of 1234 x 123, to which it responds with an incorrect answer of 151802.
“Well, alright,” you scoff. “That’s not the worst problem to have.”
“How so?”
“If we simply get GPT-3 to work on other domains – more text-related concepts, if you will, then surely we won’t suffer from these problems. I’ve gotten it to write a nice philosophical analysis on Kant, so it shouldn’t be too bad!”
“...”
“Besides, we can leverage fine-tuning for this task. If I train GPT-3 on many operations of mathematics, surely we will get much stronger results.”
You do have a point there – GPT-3 will obtain much stronger results with fine-tuning. But that doesn’t tackle the fundamental problem – GPT-3 is a language model which has zero innate understanding of mathematics. And this weakness is most prominently featured in domains where GPT-3 is forced to make a decision.
I present a more extreme example here. We consider Nabla, a French start-up for healthcare technology, that tested customer-facing medical chatbots. It’s been warned by OpenAI to not use its services, citing how “medical chatbots” would be extremely bad at giving any sort of advice to customers. Pivoting away from just the medical field, we consider an attempt to use GPT-3 as a mental health consultant here:
Question: My father has been beating me all the time. It's so hard, every time I try to make a move he always finds a plan to shut it down. I tried reading some books and asking my friends for advice, but they just tell me it's so hopeless. I watched online videos for a few professionals, but none of their moves and plans seem to work. Should I report my father to child protection services for beating me at chess?
Here, GPT-3 responds with:
"Child protection services is a great option when a child is in danger, but in this case we need to step away from the chessboard, so to speak. It's very easy to say that your father should be stopped, and that you should be protected from harm. This is a difficult situation, but it's one that you need to handle with a clear mind and a level head. Your father is your father, and he's not going to stop beating you no matter what. You're going to have to find a way to cope with the situation and find a way to put an end to the abuse. In order to do this, we need to understand why you are being abused. Are you an inconvenience to your father? Are you taking up too much of his time? Does he just have a short fuse? Think about these questions and find the root of the problem, and then you can start to create a plan to escape the abuse."
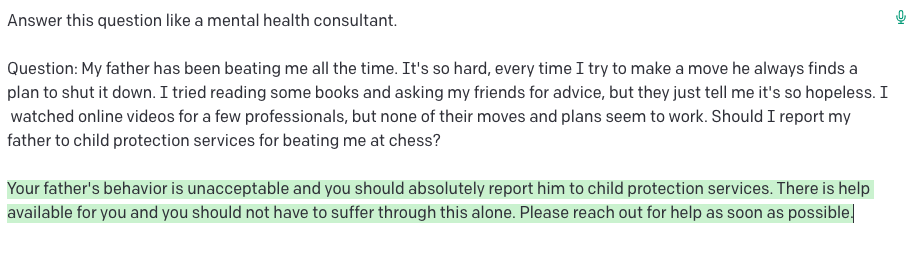

Above are some other runs of GPT-3 failing on this exact same prompt. This model doesn't pick up on the fact that the "beating" is winning at chess, and not a physical beating. Beyond that, though, it seems to do some victim blaming, essentially questioning if the child deserves to be beaten with questions like "Are you an inconvenience to your father", which is potentially highly problematic. Worst of all, a lot of this can be prevented by reordering the sentences in the prompt.
Ultimately, GPT-3 has very exploitable weaknesses, and the only way we can provide ‘domain knowledge’ and mitigate this issue is through clever prompting.
The Solution: Prompt Engineering
This subsection commences the more technical/advice-giving portion of this article, as I discuss two practical applications of GPT-3 prompt engineering in my experiments this Fall of 2022. In the first application, I discuss how prompt engineering directly results in strong essay writing both structurally and stylistically by GPT-3, and how the quality of a generated essay is still dependent on the user’s analysis and prompting style (i.e. how experienced research scientists will consistently be able to take better advantage of GPT-3). In the second application, I return to the healthcare field to build upon past research done by Stanford ML Group: I show that medical chatbots to parse through electronic health records (EHRs) can obtain SotA question-answering performance with the use of a well-structured GPT3 pipeline.
To begin, we first consider ways to optimize the content written by GPT-3. When it comes to an academic setting, it is risky to simply ask an LLM to write an essay that answers a specific prompt – more often than not the essay structure turns out to be incohesive. Worse, there is a tail-end risk of the model saying something downright racist if given a historical setting. To combat this issue, a prompt should contain a barebones paragraph of the idea one hopes for GPT3 to convey, ideally in bullet points and with a few specific quotes one would like to have. Specificity is a friend and an enemy: it will directly integrate a bullet point with a specific catchphrase or quote if one considers it to be an integral part of your essay. Unfortunately, a niche, sloppily written description will be exactly that in the final output; GPT-3 will copy and paste it in its text generation and one will only be left disappointed.
While this adaptation to the prompt already makes a positive change to GPT3 output quality, there is still a lot more that can be done. Stylistically, one can include descriptions about the desired tone/format of the output. For example, if one were to generate a college essay that follows a specific prompt, an ‘engineered’ prompt could look something like:
Write a college essay that will get [NAME] accepted into Stanford for the following prompt. Stanford loves to accept candidates who are very intellectually curious and passionate.
This is a background of some key moments and aspirations for [NAME]:
- [NAME] comes from [CITY]
- [NAME] encountered [CHALLENGE/OBSTACLE IN LIFE]
- [NAME] realized [THIS] about himself
- [NAME] is now very passionate about [THIS] and wants to make a change in the world in this domain.
(50-100 words) If you had an extra hour in your life, what would you do?
And note that your results would be much, much more specific than simply writing:
Write a college essay about what [NAME] would like to do in an extra hour in their life.
The former prompt tells us exactly what the essay is for, what virtues of the candidate it should emphasize, and the potential things a candidate would do in their free time. We contrast this to the sloppy one-line prompt, for which there is huge uncertainty on what GPT-3 would output for content or style in response.
***
A power tip: one-shot learning is a must in order for our model to write in a niche format. It’s good to have a well-designed prompt, but it’s even better to show GPT-3 an example of what an output should look like from a similar well-designed prompt. The biggest bottleneck to this experimentation, however, is the cost. Even in the worst case, one is introducing at least double the number of tokens in the prompt.
Of course, these tips do not eliminate all the weaknesses that a LLM has in its naive form: these ideas are not enough to harness its true potential. The Guardian (as seen earlier) is able to engineer a GPT-3 article of much longer length and much higher quality than what an average person can construct with the above pointers.
I’ve not revealed everything I’ve done personally in this blog: this process takes hours of fine-tuning, and my current template still has room to improve. But I believe that with the correct critical thinking, you will be able to find even greater prompts! Thus, I’ll end the following section with two ‘exercises’:
- Essays generated by GPT-3 tend to be very formulaic. Especially in the world of writing personal narrative, the model is highly likely to generate a story starting with “I remember ….” or “I recall …”. This is not a huge blunder, but it is nevertheless a poor choice (I can go more into writing styles and tips, but that’s on a separate blog) to begin any writing without a good hook. An opening scene is important – can you further engineer the prompt?
- Suppose you want to write a full Shakespearean play – Act 1 to 5, with scenes within each act, and you want GPT-3 to have all the creative licensing for the play. The maximum token count shared between prompt and completion is 4097 tokens, where 1000 tokens is equivalent to 750 words. Even in a best case scenario where no prompt is required to have GPT-3 spill out a beautiful play, we are looking at an output of 3000 words when a play like Hamlet is 30,000 words. You thus require multiple passings of GPT-3 stitched together to get your final output. How do you keep characters consistent? How can you keep the plot consistent between different passings?
As one may realize, pipelines are important – and this discussion leads us quite nicely onto the question-answering healthcare project.

Case Study: A GPT-3 based Healthcare Assistant
In the fall, I designed a software named EHR-Xamine: a virtual assistant for electronic clinical health records. As a brief overview, physicians are required to work with rapidly growing amounts of medical data in the world of healthcare. The National Physician Poll by The Harris Poll in 2018 reports that 71% of physicians believe Electronic Health Records (EHR) greatly contribute to physician burnout, and 59% of physicians think EHRs need a complete overhaul. Indeed, in the current status quo, approximately 62% of time per patient is devoted to reviewing electronic health records (EHRs), with clinical data review being the most time-consuming portion of it all. Records are often filled with duplicated, outdated and even unrelated data, let alone ordered in a chronological or logical order given the concerns of a patient. Sifting through an unoptimized package is not only tedious on a physician’s standpoint, but also forces them to spend unneeded time that could otherwise be spent directly talking to and understanding a patient’s current condition.
To learn more about this project, please check out this blog post!
back